If you haven’t heard yet, OpenAI, an organization which has gained a large amount of news coverage thanks to their large financial backing and mission to ensure that strong AI is beneficial for humanity, shifted from a non-profit to a “Capped Profit” entity. This has led to a lot of discussion about the motivations behind their move.
There is a lot of nuance to such changes, and I cannot pretend to understand the economics and details of their specific implementation. Nevertheless, I claim that this decision, and experiments like it, are a very important component of safe AI research.
Safe AI
To the public, a dangerous AI is actively malevolent. From the Terminator’s robotic grin to the human powerhouses of the Matrix, machines have malfunctioned and are out to get us.
People more familiar with machine learning realize that an AI does not have to be evil, nor does it need a system error to be a danger to humankind. An indifferent AI can be equally destructive. This is beautifully summed up by Eliezer Yudkowsky’s quote:
The AI does not hate you, nor does it love you, but you are made out of atoms which it can use for something else.
The example of a paperclip maximizer is likewise chilling: When given the task of manufacturing as many paperclips as possible, a superintelligent AI could enslave all humans to work in paperclip-producing factories, or wipe them out entirely to stop them from interfering with its plans (You can see this from the AI’s point of view in this very addicting game).
The question of safe AI is therefore: is it possible to set up the machine’s goals so that they will be aligned with ours? How do we ensure that the machines, once they arrive, will be beneficial to humanity?
Setting up the correct goals turns out much more difficult than it would initially seem because the goal must be encoded as a number, called a “loss function” (although there is research on alternatives). We can’t currently tell an AI to “make the world better”. We can only tell it to minimize infant mortality, maximize GDP, and minimize number of people dying of cancer. Notice how easy it is for a machine to misunderstand our intent: one way to achieve all of these goals is to kill all humans, and convert the entire country into factories. Then, nobody would die of cancer, no babies would ever die again, and the GDP would be astronomical.
This is not just theoretical. Anecdotes abound of researchers wanting artificial agents to do one thing, and having them do something completely different. In fact, even OpenAI had a post dedicated to this issue, where they trained a neural network to play a racing game by having it maximize score. Instead of finishing the race, the AI found that it could maximize score by going in a circle, collecting points by repeatedly crashing into things:
Imagine a genie in a bottle, trying to do the least amount of work. Saying “I wish to maximize X” needs to have doing what you want be the easiest possible way of achieving X.
Corporations Are Like AIs
An organization or company can be seen as an AI built of humans: a machine whose computational elements are human brains. I am certainly not the first to propose this, but I believe that I can convince you that this isn’t just a surface-level similarity.
The philosophy of groups and entities is an attractive topic of discussion (When does a group of cells become an organism? When does a group of people become a different entity altogether?), but my approach here will be more direct and mundane. I claim that the structure of an organization literally encodes a learning algorithm that minimizes its loss function, whatever it might be.
To show this, we can create a toy organization structure roughly encoding the idea of people working for a company. The model uses the mechanic of employees getting promoted & fired based on helping/hurting the “bottom line” (ie: loss function). You can see the full model specification here:
View Jupyter Notebook
The Corporate Ladder
To test the hypothesis that a corporation's structure encodes an optimization procedure, we set up a basic toy model. To those familiar with ML, the proposed model bears some resemblance to boosting.
Given a set
import numpy as np
import matplotlib.pyplot as pltThe model
An incoming employee
The company has 5 promotion levels, where employees with higher reward are more likely to get promoted, and employees with lower reward are more likely to get demoted.
An employee that goes below the 0 promotion level is fired, and replaced with a fresh employee.
To start off, we will use a direct promotion/demotion heuristic: any employee whose reward for a time step is over 1 standard deviation above the company average is promoted, and anyone below one standard deviation is demoted:
# Number of time steps to run
timesteps=1000
# The number of employees
n = 100
# The maximum number of promotions that an employee can have
maxPromotions = 5
firingThreshold = -1
# An employee is represented just by the mean of their reward distribution for this example.
# You can change it to something else to explore more complicated distributions
def newEmployee():
return np.random.normal()
# Given an employee, and their promotion level, output the employee and the reward they get
def rewardOutput(level, employee):
# Return random number with the employee's mean, and the employee's mean does not change
# wih time
return np.random.normal(employee), employee
# Each time step, new employee levels are computed from the levels vector, and the corresponding vector of rewards
def employeeReview(levels,rewards):
normalizedReward = (rewards-rewards.mean())/rewards.var()
# Promote and demote one standard deviation
levels[normalizedReward > 1] +=1
levels[normalizedReward < -1] -=1
return levelsGiven the above, we run the simulation, and observe the result
def runSimulation():
# All employees start at level 1
employeeLevel = np.zeros(n,dtype=int)
employees = [newEmployee() for i in range(n)]
totalReward = []
meanReward = []
employeeMean = []
for t in range(timesteps):
rewards = np.zeros(n)
for i in range(n):
rewards[i],employees[i] = rewardOutput(employeeLevel[i],employees[i])
totalReward.append(rewards.sum())
meanReward.append(rewards.mean())
employeeLevel = employeeReview(employeeLevel,rewards)
# Move people above max promotions back down
employeeLevel[employeeLevel > maxPromotions] = maxPromotions
# Fire everyone with level 0
for i in np.nonzero(employeeLevel <=firingThreshold)[0]:
#print("Replacing",i,employees[i])
employees[i] = newEmployee()
#print("With",employees[i])
employeeLevel[employeeLevel <= firingThreshold] = 0
#print("orderedLevels",employeeLevel[np.argsort(np.array(employees))],employeeLevel[np.argsort(np.array(employees))][0:int(len(employeeLevel)/2)].mean(),employeeLevel[np.argsort(np.array(employees))][int(len(employeeLevel)/2):].mean(),rewards[np.argsort(np.array(employees))])
return totalReward,meanReward
totalReward,employeeMean = runSimulation()
plt.gcf().set_size_inches(12,8)
plt.title("Average Reward Per Time Step")
plt.xlabel("Time Step")
plt.ylabel("Reward")
plt.plot(totalReward)Text(0.5, 1.0, 'Average Reward Per Time Step')
Text(0.5, 0, 'Time Step')
Text(0, 0.5, 'Reward')
[<matplotlib.lines.Line2D at 0x7f1b14aebd68>]

This is a classic optimization curve. In less than 1000 time steps, the average employee at the company is over 2 standard deviations above the population average.
This result is pretty obvious: the entire goal of the hiring/firing process is to retain the best talent and get rid of those bringing the team down. However, it is what we did not explicitly state that is most important: the average employee at the company is over 2 standard deviations above the population average at the metric being optimized.
Maurice Hilleman (creator of the measles vaccine) would probably be quickly fired at a company selling homeopathic remedies, no matter how many lives his work saved. It is also questionable how long he would have lasted at a call center. Likewise, the creator of an open-source competitor to a company's cash-cow product is unlikely to be in good graces at the company.
It makes sense that the thing being optimized is the company's direct business goals, no matter what the HR or PR departments might say about "consumer benefit"
Adding Stochasticity
My conclusions given above were a bit harsh. Let's suppose that times are good, so the company does not have shareholders breathing down the executives' necks to focus on optimizing profits (or whatever the company's charter specifies is the ultimate goal). Or maybe the company executives are simply bogged down in office politics and bureaucracy.
In such a situation, promotion/demotion might be only slightly correlated with reward. In this next example, high-reward employees have chances of promotion only 10% larger than low-reward employees. This simulates promotions and firing based mainly on other factors, be they office politics, "culture fit", or even benefit to humanity.
What does the model say now?
# Now, make the promotions and firing be probabilistic, based on performance.
# The employees are assumed to be ordered from least reward to highest
# The probability difference between promotion and demotion is just 10%, to show
# that even if there is just a tiny push in the direction of optimization...
pstart = 0.2
pend = 0.3
probabilityOfPromotion = arange(pstart,pend,step=(pend - pstart)/(n))
probabilityOfDemotion = np.flip(probabilityOfPromotion) #arange(pend,pstart,step=(pstart-pend)/(n))
def employeeReview(levels,rewards):
# Set the threshold with a uniform 0,1
promotionThreshold = np.random.uniform(size=len(rewards))
demotionThreshold = np.random.uniform(size=len(rewards))
indexOrder = np.argsort(np.argsort(rewards)) # We find the inverse of the argsort permutation to get index order
return levels + (probabilityOfPromotion[indexOrder]>promotionThreshold) - 1*(probabilityOfDemotion[indexOrder]>demotionThreshold)
totalReward,employeeMean = runSimulation()
plt.gcf().set_size_inches(12,8)
plt.title("Average Reward Per Time Step")
plt.xlabel("Time Step")
plt.ylabel("Reward")
plt.plot(totalReward)Text(0.5, 1.0, 'Average Reward Per Time Step')
Text(0.5, 0, 'Time Step')
Text(0, 0.5, 'Reward')
[<matplotlib.lines.Line2D at 0x7f1b1477da58>]

After 1000 time steps, the average employee is about half a standard deviation better at optimizing reward than the population at large. This means that the average employee is still a bit more focused on the company's business goals than the average person.
Analysis
All that the above simulations specify is that a company's hiring and firing method ends up encoding a simple algorithm, optimizing for its goals. For a company focused entirely on its goal, it will hire and promote employees who are likewise singularly focused on that goal. To be clear: there is nothing wrong with this if those goals are correlated to benefit to humanity. There is also nothing wrong if the goals are orthogonal to benefit to humanity.
The issues only start if the thing being optimized ends up being against humans' best interests. For the full discussion please refer back to the blog.
Summarizing the results, we get the following:
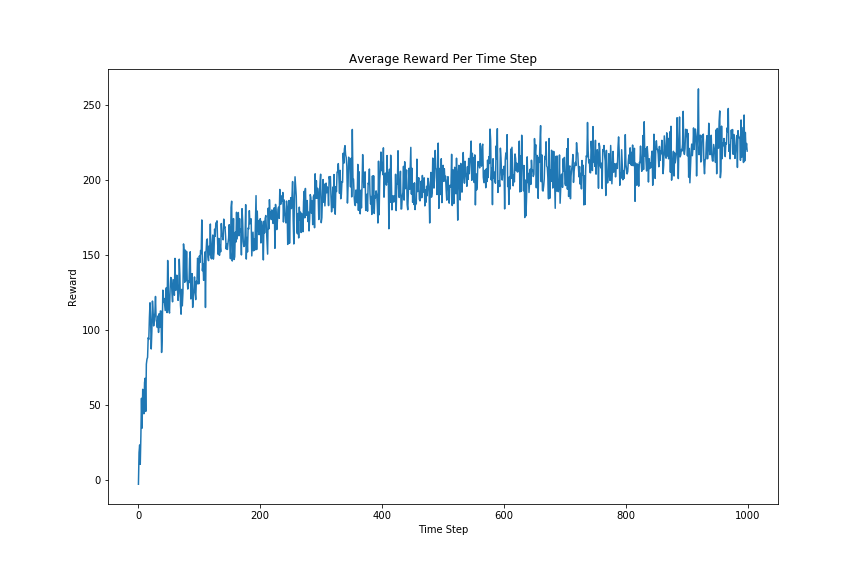
This plot shows a curve familiar to everyone who has played with machine learning - at the beginning, the organization’s employees are randomly chosen, and over time, those who are most focused on the organization’s goals are promoted, and those who do not have the same singular focus are fired, resulting in an organization where on average, a member is over 2 standard deviations above the general population when it comes to focus on the company’s loss function.
Just like with an AI, this is not bad by itself - all it is saying is that the organization will end up having behavior generally similar to that of an AI which is given the same task. If the organization’s loss function stands against benefit to humanity, it will select for members who are either good at ignoring/giving excuses for cognitive dissonance, or simply care about having a job to feed their family more than the nebulous fate of faceless numbers in a database.
It could be argued that since people make up an organization, there is only so far the organization could go before its constituent elements would rebel. While there might be an element of truth to this, it looks like the answer to “how far” is far, FAR beyond what can be considered acceptable:
Our malleability and ability to cooperate as part of a group might plausibly be the single most important trait that has led to the rise of human civilization[1], but it also makes organizations and groups of humans behave in sometimes terrifying and unscrupulous, even murderous ways - exactly the traits that we fear will show up in AI.
To end this section on a positive note, it does seem like there might be a line most humans will not cross, no matter what their group’s goals, and that is performing an action that will guarantee total human extinction. So indeed, unlike a “pure” AI, a machine made of humans does have a limit… somewhere between “kill all the jews/cambodians/tutsis/etc” and “sterilize the planet”.
Maybe that’s not such a positive note after all…
The Corporate Loss Function
Let’s recap. I have established that organizations behave like non-human AIs, optimizing whatever goal they were tasked with: even just hiring and firing workers is sufficient to guarantee this. I have also claimed that these machines being made of humans does not stop them from behaving in decidedly anti-human or even genocidal ways, if that ends up being what they try to optimize.
The question, then, is what are corporations optimizing? I will focus on corporations here, but the same ideas apply to governments, religious groups, and any other large organized group of humans.
I’ll use the example of Facebook since it seems to be a popular scapegoat these days. Facebook’s purpose, according to its certificate of incorporation is:
The purpose of the corporation is to engage in any lawful act or activity for which corporations may be organized under the General Corporation Law of the State of Delaware (“General Corporation Law”).
There is nothing about social networks here - Facebook as an entity exists to do whatever it damn-well pleases, so long as it is not explicitly against the law. The company could completely restructure itself as a producer of lollipops or machine guns if it so desired. ML practitioners will realize that this isn’t a loss function at all - it is a regularizer.
To those unfamiliar with the terminology, a regularizer is a term you add to your loss function to nudge an optimizer, which might converge to an undesired result, towards an optimization point with good properties. The regularizer here consists of the laws and regulations governing corporate behavior. A corporation gets punished if it dumps toxic waste into rivers, or otherwise behaves in a manner society deems unacceptable.
Of course, examples immediately come to mind of corporations that were caught doing all sorts of illegal things. This is because a penalty for breaking the law is only paid if it one caught. Just like a regularizer multiplied by 0 has no effect, laws have no effect unless there is a non-negligible chance of them actually being enforced, and having a larger negative effect than the benefits of unwanted behavior[2].
That being said, Facebook’s loss function is not fully specified by its articles of incorporation. Let’s look at the company mission:
Facebook’s mission is to give people the power to build community and bring the world closer together. People use Facebook to stay connected with friends and family, to discover what’s going on in the world, and to share and express what matters to them.
Whatever you think of Mark Zuckerberg, thus far his company has been faithfully optimizing this objective, despite the darker parts of human nature it has exposed. Even people at the company noticed that the goal seemed to be blindly pursued, which was raised in 2016 with The Ugly memo:
We connect people. Period. That’s why all the work we do in growth is justified. All the questionable contact importing practices. All the subtle language that helps people stay searchable by friends. All of the work we do to bring more communication in. The work we will likely have to do in China some day. All of it. (…) That can be bad if they make it negative. Maybe it costs someone a life by exposing someone to bullies. Maybe someone dies in a terrorist attack coordinated on our tools.
The mission can be seen as the current loss function that is powering the corporation. This isn’t the end, though - there is another level above the company’s mission.
In a public corporation, shareholders hold power to modify the mission. This is known as a “pivot”. Big investors, such as banks, seem largely interested in ensuring that the mission statement, whatever it may be, guarantees a profit. Notice that shareholders here are not people[3] - they are usually other corporations and organizations.
To get “Safe AI”, start with “Safe Corporations”
Corporate law and AI safety have much more in common than is initially evident: they both have the goal of ensuring superhuman entities are beneficial to humanity. The only difference between a corporation and a strong computer-based AI is that a strong AI is hypothesized to be much faster.
If you want to research safe AI, don’t waste time with hypotheticals. You have a very easy problem statement: how do you set up government regulations, default corporate law, as well as the definition of a corporation to guarantee that the entity won’t behave in an anti-human manner? If you can’t manage it in the real corporate environment, then you have no chance against an entity that thinks and acts thousands of times faster than a corporation.
Similarly, board members of a corporation should be aware that the corporation will interpret the company’s mission literally and blindly. Sure, maybe the current CEO has humanity’s best interests in mind, but the company is not the CEO. The CEO can die, leave, or be fired. Each such departure and hire is just another step in the corporate optimizer.
The same reasoning suggests that jailing an executive for crimes committed in pursuit of the company’s mission is ultimately ineffective long-term, for the same reason as previously stated: if it is beneficial for the corporation to perform illegal actions, the optimizer will eventually select another executive willing to perform them.
Finally, there is a simple test of corporate and AI safety. If the corporation’s very existence was causing harm to humanity, would the corporation/AI commit suicide? That is, does there exist an internal watchdog with the power to terminate the company, or otherwise is there a government regulation that when broken leads to the death sentence for an entire corporation?
The only such mechanism that I am aware of is corporate bankrupcy and liquidation. Unfortunately, this mechanism is focused on corporations failing in a profitability goal. There seems to be no equivalent mechanic for corporations that fail at being beneficial to humanity - a corporation cannot go to jail for actions that would warrant life sentences were they done by humans.
OpenAI’s Experiment
Given the above discussion, I believe that there should be a lot more experimentation in specifying loss functions for corporations. In my view, OpenAI’s new structure is exactly a step in that direction.
On the one hand, you want to restrict an AI’s space of actions to limit the harm it can do, but on the other hand, the resulting safe AI must be competitive with unsafe AI, otherwise unsafe AI will always win.
As far as I understand, this matches perfectly with the motivations specified for OpenAI’s “Capped Profit” entity. It remains to be seen if their specific setup is sufficient to guarantee safety, but at least they seem to recognize the problem!
Human individuals are weak and useless in nature without the power of our entire civilization providing them with technology, communications, and support. Think of humanity’s greatest achievements, such as visiting the moon. This involved thousands of people working together to create something with complexity beyond the abilities of a single human - no one human understood the intricacies of everything from mining metals to the circuit design of each subsystem of the lunar module. ↩︎
The machine can also avoid a loss by modifying the regularizer itself. The entire lobbying industry is built for this purpose. ↩︎
I believe that corporate personhood comes from the flawed intuition that a group of people behaves similarly to a big human. I hypothesize that a corporations behave more similarly to a pure AI than a human when given enough time (see the hiring/firing model above). ↩︎