We’re going to present “Efficient Identification in Linear Structural Causal Models with Auxiliary Cutsets”, a joint work with Carlos Cinelli and Elias Bareinboim, at ICML 2020. Like my previous paper on the topic, explained here, this work is quite technical, and requires a relatively strong background in statistics.
Nevertheless, the core ideas underlying our method are quite approachable. This post serves as a stand-alone introduction to the problem of identification in linear models, and gives a taste of our algorithm. It is my goal to make the first section accessible to anyone who can understand a scatter plot and a linear regression, the second section comprehensible to those with relatively strong mathematical background, and the remaining sections focused on those who have dealt with path analysis or linear SCM before.
You can view our presentation here.
What Problem Are We Solving?
Suppose we’re medical researchers, and our goal is to find out if an existing medicine helps in fighting a new disease. We gather a dataset of people who voluntarily took various quantities of the drug to treat other conditions, and measure the amount of a biomarker in their blood (such as antibodies to the target virus). The more biomarker, the better. We get the following dataset:
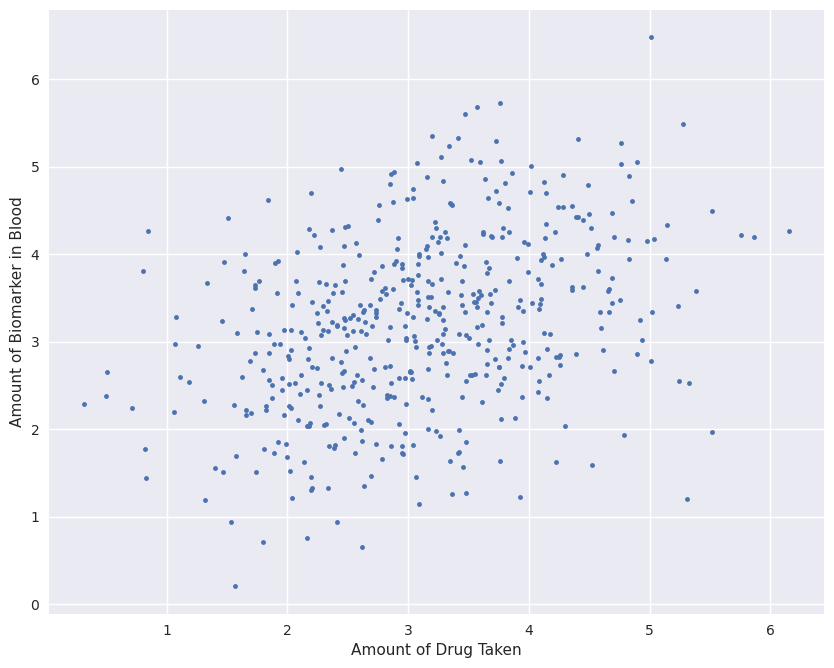
The first thing that we do to analyze the data is to find a linear best-fit. By performing a least-squares regression, the slope of the line will tell us whether the amount of drug taken is positively correlated with the amount of biomarker. We fit
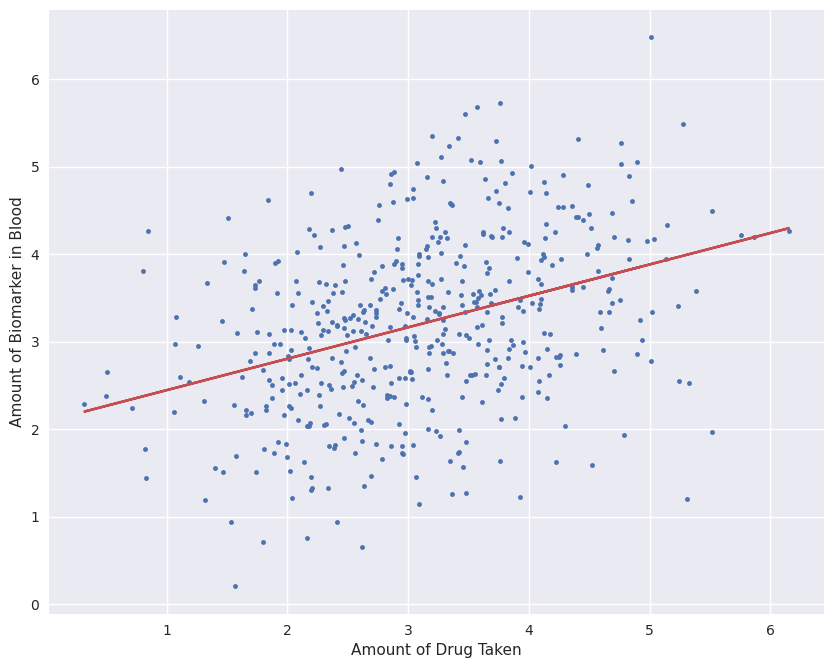
The slope is clearly positive, meaning that the people who took more of the drug fared better on average than those who didn’t. With this clear result, we happily give the new “miracle drug” to the entire population, which gives us a new dataset:
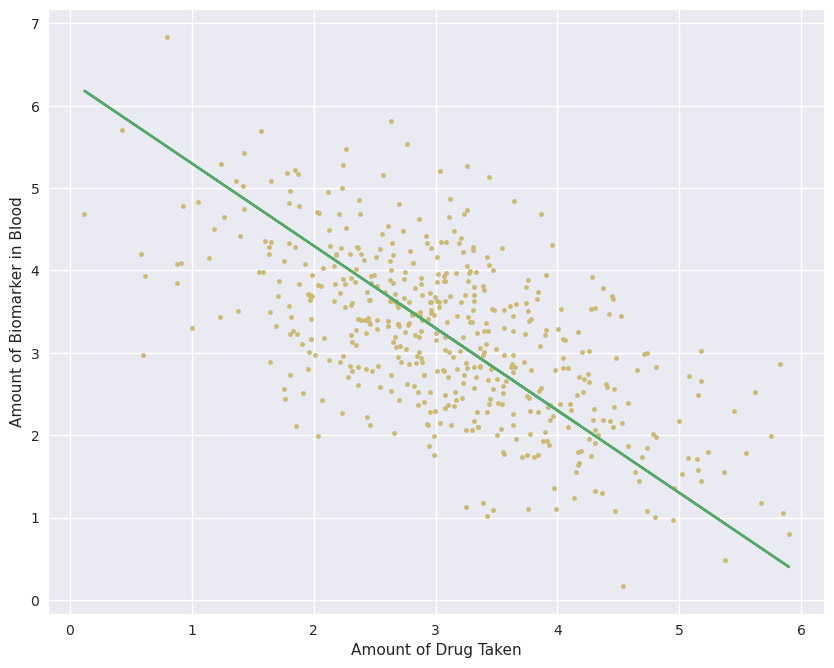
This new dataset (yellow points) seems to show the opposite result from the original data (blue points). There is a clear negative correlation between the amount of drug taken and the biomarker of interest, meaning that the drug actually hurts people! What went wrong with the original dataset? Or, more importantly, given only the original data (blue points), could we have found out that this drug is harmful? The question of whether we can find the true causal effect from only observational data is usually called the problem of “identification”.
This problem is impossible to solve without information beyond the data, namely our knowledge of the context in which the original data was gathered. Here we will encode this knowledge through what are known as “Structural Causal Models”.
Encoding Context: Structural Causal Models
Here, we focus on linear models. A linear Structural Causal Model (SCM), is a system of linear equations that encodes assumptions about the causal relationships between variables. When performing the linear regression, we implicitly assumed that the amount of drug taken,

In the above,
Let’s see what a linear regression computes here. We set up the regression equation:
Recall that the covariance between
Show the derivation
Start out by expanding out the least-squares equation, exploiting the fact that normalized variables have variance 1:
Then, to find the value of
A regression computes the covariance between variables when variables are normalized… What does that have to do with
Here, the covariance of
It turns out that the medicine in question is extremely expensive, so only the rich can afford to take large amounts. Wealthy people are more likely to get better anyways, simply because they don’t need to keep working while they’re sick, and can focus on recovery! The true model was in fact:

Since wealth was not gathered as part of the dataset, it is a latent confounder, represented by a correlation between the
The first term in the result,
One fix for this would be to gather the wealth data explicitly from every person in the study. However, some people might not want to share such information. All is not lost, though. Suppose each subject in the study has a doctor who recommended taking the drug lightly, strongly, or anywhere in between. The amount of the drug they took was directly influenced by their doctors’ recommendation. Critically, the decision of the doctor was not based on the wealth of the patients, or other confounders (e.g, the doctor was recommending the drug for another condition, unrelated to the biomarker of interest). If we gather a new dataset which includes this recommendation level, we get:

In this situation, regressing
If our model is right, the desired causal effect can be solved as a ratio of two covariances/regressions! This method is usually called the instrumental variable, and is extremely common in the literature [1]. Estimation of that ratio is typically achieved using 2-stage least squares.
2-Stage Least Squares
As the name suggests, rather than using a ratio of two regressions, a 2SLS uses the result of one regression to adjust the other. In particular, first the regression
Then, the resulting
If we were to perform a regression
Despite the procedure being different, the end effect is the same: the resulting value corresponds to the same ratio of covariances that was derived above.
In general, no single regression gives the desired answer, it is only through a clever combination of steps based on the underlying causal model that an adjustment formula can be derived, giving the causal effect.
Finding this adjustment formula, given our model of the world (structural equations and causal graph) is the goal of identification. If such a formula exists, an identification algorithm would return it, and if not, the algorithm would say that the desired effect cannot be found.
Most state-of-the-art methods for identification look for patterns in the causal graph which signal that mathematical tricks like the one shown above can be used to solve for a desired parameter. Such graphical methods focus on paths and flows between sets of variables, as will be demonstrated in the next section.
Auxiliary Variables
Suppose we have the following structural model, and want to find the causal effect of

Expanding out the covariance between
Experts in the field might notice that a simple regression of
We turn to Auxiliary Variables [4], allowing usage of previously-solved parameters to help solve for others. In this example,
This new variable
This method misses some simple cases, though.
Total Effect AV
And here, finally, is where our paper’s contributions begin. In the following example, the edges incoming into

Nevertheless, the total effect of
Once again, a bit of math shows that this AV can be used to successfully solve for the desired
Of course, the situation becomes much more complex once there are multiple back-door paths between
The path in purple is double-subtracted!

The key insight needed to solve this problem is that the total-effect of
Yay, it worked!

This is all great, but how exactly does one find the value of these partial effects, so that they can be removed from
Partial Effect Instrumental Set (PEIS)
The PEIS is a method to find exactly the partial effects needed to contruct the proposed new AVs. We assume that readers of this section are familiar with instrumental sets [5], or have read the “Unconditioned Instrumental Sets” section of the post from our previous paper. The core takeaway of that section is repeated here:

It turns out that the exact same type of system will solve for the desired partial effects! The main difference now is that instead of being restricted to parents of the target (as in the IS), we can use any nodes. In this case, we use

With the PEIS and the total-effect AVs as defined above, it is now possible to identify a new class of parameters missed by previous efficient approaches.
Auxiliary Cutsets & ACID
Our paper uses these insights to develop a new algorithm for identification which recursively finds total-effect AVs, identifying successively more parameters in each iteration. Surprisingly, this method turns out to subsume the generalized conditional instrumental set, which has unknown computational complexity, and has NP-Hard variants [6 kumorEfficientIdentificationLinear2019]. Critically, our algorithm finds optimal total-effect AVs and their corresponding PEIS in polynomial-time, being the first efficient method that subsumes generalized instrumental sets.
In fact, to the best of our knowledge, it subsumes all polynomial-time algorithms for identification in linear SCM, as can be seen in this figure taken from the paper:
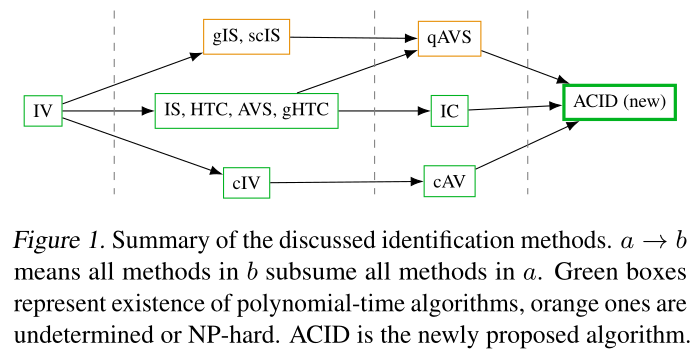
To find out details of our algorithm, and to see how all of this was proved, please refer to the paper!
References
- Angrist, J. D., Imbens, G. W., & Rubin, D. B. (1996). Identification of Causal Effects Using Instrumental Variables. Journal of the American Statistical Association, 91(434), 444–455. https://doi.org/10.2307/2291629
- Wright, S. (1921). Correlation and Causation. Journal of Agricultural Research, 20(7), 557–585.
- Pearl, J. (2000). Causality: Models, Reasoning and Inference.
- Chen, B., Pearl, J., & Bareinboim, E. (2016). Incorporating Knowledge into Structural Equation Models Using Auxiliary Variables. IJCAI 2016, Proceedings of the 25th International Joint Conference on Artificial Intelligence, 7.
- Brito, C., & Pearl, J. (2002). Generalized Instrumental Variables. Proceedings of the Eighteenth Conference on Uncertainty in Artificial Intelligence, 85–93.
- Van der Zander, B., & Liśkiewicz, M. (2016). On Searching for Generalized Instrumental Variables. Proceedings of the 19th International Conference on Artificial Intelligence and Statistics (AISTATS-16).